
The Nilson Report survey showed that banks and merchants lost more than $28 billion from it in 2020. Meanwhile, according to the same study, the level of damage in 2030 will increase further to 49.32 billion.
In this article, we are going to talk about the tools companies use to fight against fraud. We will also analyze why, despite all the innovations, the number of financial losses will still increase.
Globally, all card payments can be divided into two large groups:
- CP (card present) transactions, which include payments made with a physical card. In other words, these are the purchases in stores where the user inserts or holds the card in the terminal.
- CNP (card not present) transactions, that is, purchases made in online stores.
It is traditionally considered that the first type of payment is less exposed to the risk of fraud. The reason is that in this case, the fraudster needs to steal the physical card and know its PIN code.
Online purchases, on the contrary, do not require any contact with the victim. A hacker can break into a bank's database or use phishing to obtain data on thousands of accounts at once. Often, this compromised data later appears on the black market. According to CardRates, those prices can range from $5 (for a card number with a CVV code) to $30 (for a card with "full" information, such as the date of birth of the owner, SNN, etc.).
The difference between CP and CNP directly affects the commission that stores have to pay processing centers for transactions. Due to the high proportion of fraud and chargebacks in online payments, the commission here is much higher. It happens because processing centers take their increased risks into account and set higher commissions for online stores.
As a result, we see that the growing popularity of online shopping has a direct influence on the volume of fraud. Customers are increasingly rejecting less risky CP payments in favor of more risky CNP.
It became especially noticeable during COVID-19 when two simultaneous events affected card fraud statistics. On the one hand, international tourism virtually ceased to exist. According to various estimates, the fall was from 60% to 90%. On the other hand, the volume of online shopping rapidly increased. According to Digital Commerce 360, it received a 13% increase due to the lockdown.
Due to the decrease in tourist flow, the number of pickpocket operations has also scaled down. Moreover, fewer travelers made card payments in dubious stores in developing countries. As a result, there has been a significant decrease in CP fraud.
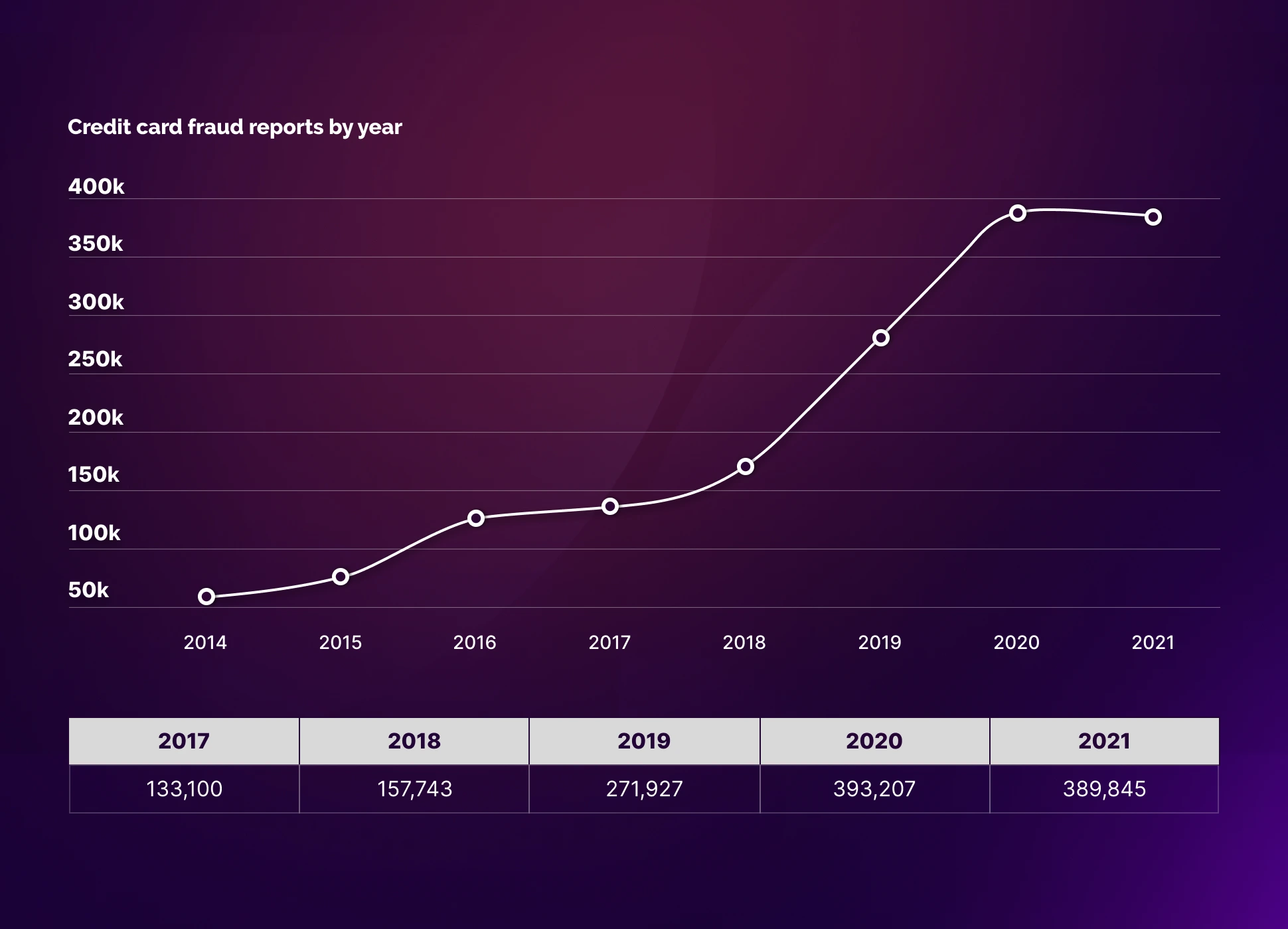
On the other hand, the growth of online payments has directly affected the growth of CNP fraud. The more often people made purchases online, the more cases of fraud the authorities recorded in this segment.
These two behavioral changes (the decrease in tourist traffic and the growth of online shopping) could have balanced each other out and left the total fraud figure at the same level as in the previous years. In practice, we have a huge cumulative impact.
So what's the reason? Why, while the online commerce market in the US increased by 32% (of which 13% was due to COVID-19 and the remaining 19% was caused by natural growth), the number of fraud cases jumped by almost 50%?
The reason is that the banks, when faced with the coronavirus, were not ready for effective monitoring of suspicious transactions and simply could not detect numerous fraudulent transactions in time.
But before we get into the reasons behind this situation, it is worth saying a few words about how financial corporations in general are reacting to CNP fraud.
There are two models for analyzing client operations:
A rule-based model
It allows financial analysts to manually determine the criteria for suspicious transactions. If a transfer falls under these definitions, the bank blocks it for further clarification.
Examples of such restrictions and "red flags" include:
- an unexpected card payment several hundred miles away from where the customer lives;
- a large number of transfers to other users' newly created accounts;
- the multiple profiles that are registered under one IP address.
This kind of analysis is easy to implement in a company. Being a practice that doesn't require vast resources, it fully complied with the requirements a decade ago by blocking most of the fraud. But as technology has evolved, fraudsters have learned how to circumvent these restrictions. All it takes is knowing the specific rules a company has and trying to follow them. For example, changing IPs when you sign up for multiple accounts or waiting a certain number of weeks before activating a card (so it doesn't qualify as "freshly created").
As a result, besides the rule-based model, an algorithmic model has emerged.
An algorithmic model
It is another way to monitor suspicious transactions. It is based on machine learning and complex mathematical models. Instead of analysts, powerful computers analyze millions of legitimate and non-legitimate transactions and find differences between them.
Thus, there is no single parameter for the system to assign a red flag. The same item or event can be legitimate for one user but indicate potential fraud for another.
For example, we have customer #1, who exclusively uses an Android smartphone. Let's assume that all of his activity takes place in Toronto and that his payment amount never exceeds $100. Then, if he suddenly pays $300 for gasoline in Michigan with an iPhone, the security systems will immediately signal a suspicious transaction.
At the same time, customer #2's payment may raise no suspicions because his digital portrait indicates frequent travel and use of multiple devices.
The main issue with an algorithmic model is that in order for it to work correctly, the computer must be "fed" with as many different operations as possible, on which it will be trained. And, while it does not cause problems with standard legal transfers, it does in the case of fraudulent ones.
According to statistics, only 1 in 10,000 transactions is fraudulent. It means that even in an array of a million transactions, only 100 will be illegal. It is obvious that this is not enough for the correct setting of the algorithm.
And now we come to the reason for the huge jump in CNP fraud during COVID-19. A significant percentage of customers had never made online payments before the pandemic. Thus, banks simply did not have enough data on these users' online activity to distinguish between standard and abnormal behavior on the Web. So, when banks were flooded during the lockdown with a stream of online payments from people who were doing it for the first time in their lives, the security systems simply could not cope with detecting fraud.
That is why it is crucial for every company to start implementing artificial intelligence as early as possible and to start training their algorithms now. After all, the more information is gathered, the more accurately the monitoring systems work. If you're interested in integrating ML and AI into your organization, just leave a request and we'll get back to you.
It's important to note that neither approach is perfect. In the case of the rule-based model, it's relatively simple for a fraudster to circumvent the protection. However, the system itself is easy to implement and doesn't require much computing power. The algorithmic model, on the contrary, requires powerful and expensive computers that can analyze millions of transactions in real time.
The optimal solution is a hybrid format combining both variants. In this case, the critical role is given to specialists capable of setting the right balance between the systems. This will ensure sufficient security on the one hand and speed of transaction processing on the other.
2 ways to detect suspicious activity
Both rule-based and algorithmic are models that act as conditional arbiters. They define the limits within which a transaction is considered legitimate. As soon as a payment exceeds these limits, the security system is triggered.
But any arbitrator's decision is based on the information received about the client or transaction. And there are two big groups.
Transaction analysis
It is based on payment analysis using the signature method, i.e., revealing the signs that are typical of fraudulent transactions. These can be relatively simple signatures, such as too frequent transactions (8 payments per minute), transactions for a large amount (several times the standard amount). Or rather complex like an abnormal increase in activity in a certain user group.
There can be hundreds of such triggers, and each one has its own internal weight. And since the volume of operations is almost always a multiple of the number of clients, it is only possible to process this entire volume of data using an algorithmic model and machine learning. Finding complex relationships in manual mode is clearly not possible. Another disadvantage of transaction analysis is the constant need to find new rules and triggers, edit them, and create new ones.
Despite the possible different approaches to machine learning, they all boil down to the same model described in the figure below.
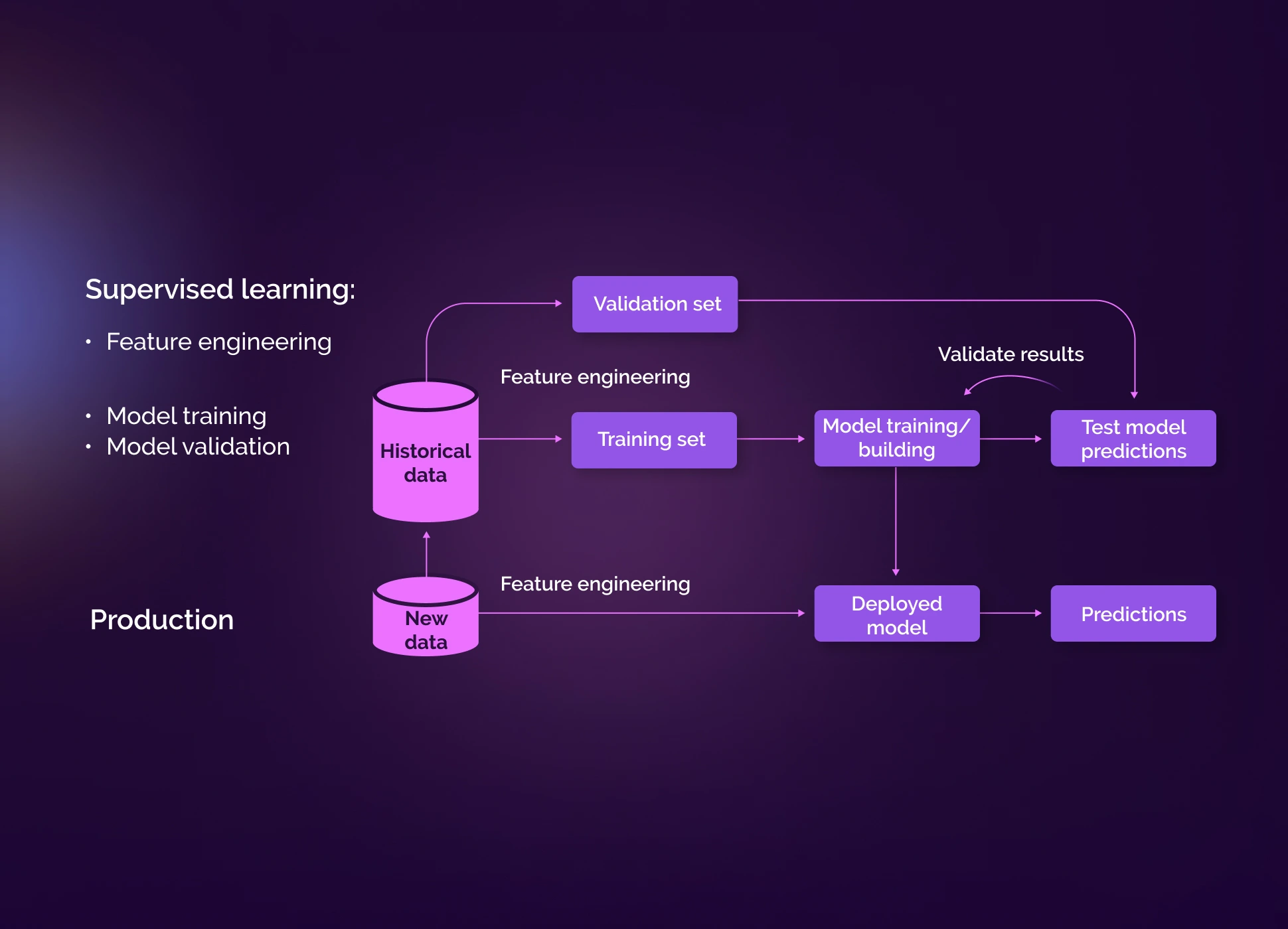
When a new transaction is made, the systems inquire about the historical data of previous transactions. This way, they come to a clear conclusion about the validity (fraudulent or legal) of the transaction. Based on this information, an assumption is made about the active transaction.
The following are the five primary issues with machine learning:
Behavioral change. The digital portrait of customer purchases tends to change depending on the time of year, holidays, or weekends. This means that it's impossible to define a static model that will validate all user transactions. Let us give you a simple example. If a customer's card, which had hardly been used before, has started to be used in large quantities, it may be a hack. Or it may just show that the card owner has started the preparation for Christmas by buying presents for loved ones.
Instant reaction. Security systems need to detect the safety of a transaction in real time, taking a split second to analyze it. It often requires a lot of processing power.
Learning imbalance. As we wrote above, the number of fraudulent transactions is 2-3 orders of magnitude lower than the number of valid transactions, which significantly complicates the learning process. To overcome this problem, we sometimes have to involve additional strategies, such as loss weighting or sampling.
Categorical characteristics. When you make a transaction, the bank receives not only numerical information, which is then easily processed by algorithms, but also categorical information (card type, terminal, etc.). This part of the data cannot be integrated in raw form. Therefore, in order for systems to work effectively, they have to be initially transformed into a comprehensible form. This is usually done through deep learning approaches or a graph-based transformation.
Efficiency systems. There are two extremes in detecting fraudulent transactions. The first is when systems are tuned for maximum detection of fraud, but the number of accidental blockages (false positives) increases. The second one is when, on the other hand, the number of incorrectly predicted cases tends to zero, but the bank misses a fraction of the real fraud. The problem is that there is no consensus on where to draw the line to achieve balance.
Session analysis
Unlike transaction analysis, it does not look for suspicious activity. Instead, it collects all available information about the user's device and creates a digital fingerprint of the user. Session analysis includes not only a client's IP but also the speed of typing, screen orientation, swipe frequency, etc. As a result, algorithms can quite accurately and uniquely identify a user and provide a high level of protection.
Session analysis systems can detect fraud even if the user was unknowingly duped by the criminals and solely gave up access to his or her account. For instance, if the fraudster contacted the client posing as a bank employee and persuaded him to install the required program or forced him to reveal the password. In this case, the use of transaction analysis alone would not have saved the customer from hacking, as the access would have been lost before any operations were performed.
To combat this kind of social engineering, security systems often monitor the presence of an active call on a customer's phone or screen recording software when the customer makes a suspicious transaction. It may signal potential danger.
As a result, session analysis becomes a critical layer of protection in cases of mass user data breaches or phishing. It is able to detect leaks before any transactions take place.
And finally, session analysis can be used either in combination with transaction analysis or separately from it. If we're talking not about banks but, say, online stores' loyalty systems, where the customer is only able to collect bonuses, then the analysis of a digital fingerprint of the user's device is enough to provide protection. In this case, a company doesn't have any complicated structure of transactions between clients that would require monitoring.
All of this leads to the conclusion that the use of a particular method depends entirely on the tasks at hand. When a company can meet all of its security needs with a single session analysis (personal accounts in online stores, referral programs, loyalty systems), the options are numerous. However, in many of these cases, users do not make any transfers to one another. In the case of banking security, it is critically important to approach the issue comprehensively. It is vital to analyze both the digital fingerprints of customers' devices and the structure of their transactions. It is especially important given the information mentioned above on how banks weren't prepared for the influx of online payments during COVID-19 due to a lack of transaction knowledge.
If you are interested in detecting and preventing fraud in your company, please contact us. Our specialists have extensive experience fighting banking fraud and will be happy to share their knowledge with you.
